
The Case for Causal Data Science and AI
Advancements in machine learning have led to the ability to use deep learning for AI-based tasks that typically draw correlations and associations from static datasets. This is incredibly impressive in certain use cases such as financial fraud detection and AI-learned photo object recognition. However, this kind of AI cannot interpret cause and effect, or why the associations and correlations exist. For non-fixed data, and arguably the real-life world, machine learning models fail to address changing conditions and accuracy is severely impacted. The industry has been using the same machine learning techniques for several decades which is limiting AI from being truly smart and able to perform the function we're hoping it will.

"Correlation does not imply causation" is a commonly used mathematics concept describing that just because two things correlate doesn't necessarily mean that one causes the other. When applied to data science and machine learning, causal knowledge is the key component to making effective strategic decisions within business. In this blog post, we explore how approaches to data science and AI must change from correlational-based to causal if being used for decision making in the real world.
Why causality?
The rise in machine learning and AI-based applications has led us to believe that AI should be intuitive and human-like. However, machine learning is failing us as it's not enough to identify patterns and even make predictions - user behaviour is very complex and may not follow pre-agreed rules. When it comes to effectively using data to gather insights for decision making it can be difficult in real-world scenarios to truly understand the cause of a result from analysing the vast amounts of data organisations hold, making it hard to predict accurately and improve performance. In order to make the most of machine learning, we need to introduce nuances and complexity through cause-and-effect networks.
Causality states that a change in the value of one variable will cause a change in the value of another variable meaning one variable makes something happened to another. This is referred to as cause and effect. It's about understanding the complex chain from instigation to outcome.
How does causality actually work?
Here's an example to help illustrate this:
A marketing team notices a peak in web traffic to their website shortly after they post a new blog.
However, they don't know for sure if the latest blog post was the true cause of the traffic or if it's because of a recent product launch, piece of PR in a newspaper or the current sale that is being promoted.
It's likely that it could be a mix of these activities but marketers want to understand how much of each variable can be attributed to the increase in visits. By simply saying that there's a correlation between increased web traffic and new blog posts, there is no real gain in insight. Without accounting for all possible factors, you can't be certain it is the variable being tested that is actually responsible for the effects.
Causality helps people understand data from a wholly new perspective so that they can make informed decisions. In the case of the marketing team, the most effective way to determine causation is to conduct marketing experiments. Casual inference can help you understand which correlations are the most likely reasons for the behaviour you're analysing.
The three levels of causality
Judea Pearl, computer scientist and philosopher known for championing the probabilistic approach to artificial intelligence and the development of Bayesian networks came up with a three later causal hierarchy that helps people understand what kind of questions can be answered with causal inference.
Seeing
The first and ‘lowest' level is association (seeing), and is everything you can learn from observation alone. An example of a question is, "What does a survey tell us about the election results?" Answering these questions is typically possible with current machine learning methods and correlation as association can be inferred directly from the observed data.
Doing
The second level, intervention (doing) involves not just seeing what is, but changing what is seen. For example, “What happens if we increase the price of an item by 50%?”. Using past sales data to predict this wouldn't provide an accurate result, as market conditions would have inevitably changed since the last price increase.
Imagining
The third and top level is called counterfactuals (imagining), the causal model of modern humans. Typical questions at this level include things like “What if I had acted differently?” and “Was it X that cause Y?”.
No counterfactual question involving retrospection can be answered from purely interventional information, such as that acquired from controlled experiments; we cannot re-run an experiment on subjects who were treated with a drug and see how they behave had they not been given the drug.
Counterfactuals, the most powerful level within the hierarchy, shows us why machine learning methods based on just reasoning by association prevent us from understanding the truth about novel actions. A confounder is an unmeasured third variable that influences both cause and effect and needs to be causally related to the dependent variable. Let's look at an example: higher ice cream consumption may be associated with a high probability of sunburn. This doesn't necessarily mean ice cream is the cause of sunburn. Instead, the confounding variable is hot weather as it causes people to spend longer periods of time outdoors and eat more ice cream.
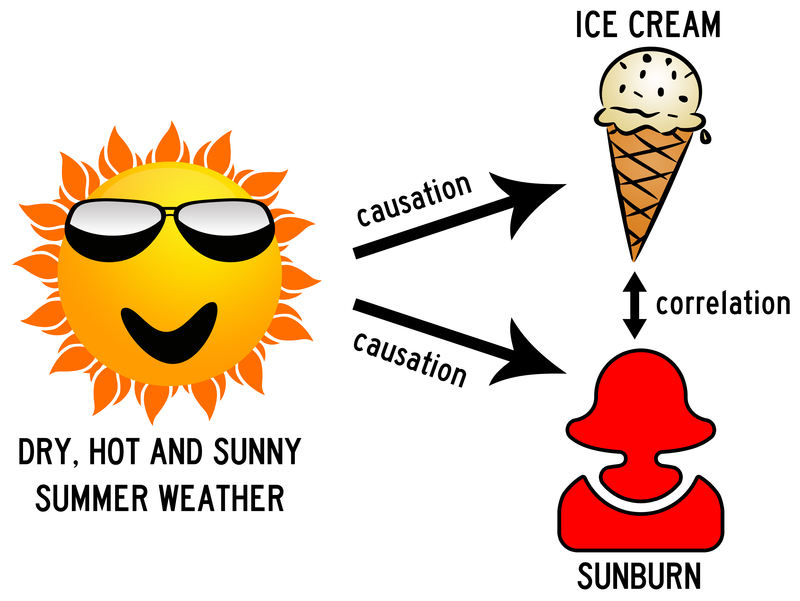
It is clear that data scientists should look toward embedding AI algorithms with the capability to find causes. Otherwise, AI is still stuck at the first rung of the ladder of causation.
Business use cases
In healthcare, causality is starting to make a big difference in how scientists approach experiments, how clinical decisions are made and how healthcare outcomes are ultimately affected. This recent paper shows that the inability to distinguish between correlation and causality in diseases can result in incorrect diagnosis or treatment.
In predictive analytics, causality is important: understanding the reasons why something happens allows businesses to better demystify questions, helping with strategy. For example, why aren't customers aren't engaging with a specific product? What is the reason for a high bounce rate on a landing page? Without causation and understanding of bias, there's a lack of actionable insights to explain the predictions being made in a machine learning platform.
In finance and specifically the world of stock market data, knowing the underlying causes of volatility is key to being able to effectively manage risk and find stock opportunities. Inferring causal interactions in financial markets is being tested, for example, in this paper in which researchers were aiming to find relationships between multiple variables based on the estimated volatility of a time series.






